Why do we need the JSON Web Token (JWT) in the modern web?

Mariano works in Claranet Italia, where he daily helps companies succeed using cloud and microservices.
He's also an AWS Authorized Instructor and AWS Community Builder.
Hold on tight: the HTTP protocol is terribly flawed and when it comes to user authentication this problem screams loudly.
For a long time we, as developers, fought with it: sometimes with good results, sometimes not, but we thought we were happy. Unfortunately, the web moves fast and many of these solutions were getting old too quickly.
He who hesitates is lost…
Later on, a group of people realised that it was time to stop fighting with the “problem” and try to embrace it. The result of that epiphany is called JSON Web Token (JWT for short) and here we will try to tell its story…
Once upon a time
Suppose you have a REST API (e.g. GET /orders) and you want to restrict access to authorized users only.
In the most naïve approach, the API would ask for a username and password; then it will be searched in a database for whether those credentials really exist. We check for authenticity. Finally, it will be checked if the authenticated user is also authorized to perform that request. If both checks pass, the real API will be executed. It seems logical.
A problem of state
The HTTP protocol is stateless, this means a new request (e.g. GET /order/42) won’t know anything about the previous one, so we need to reauthenticate for each new request (fig.1).
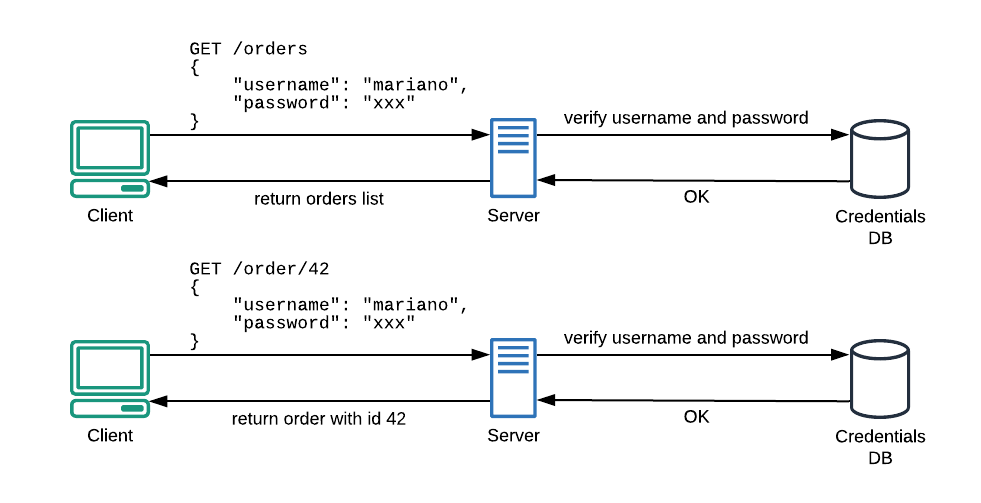 Fig. 1 — Due to the stateless nature of HTTP protocol, every new API request needs a complete authentication.
Fig. 1 — Due to the stateless nature of HTTP protocol, every new API request needs a complete authentication.
The traditional way of dealing with this is the use of Server Side Sessions (SSS). In this scenario, we first check for username and password; if they are authentic, the server will save a session id in memory and return it to the client. From now on, the client will just need to send its session id to be recognized (fig.2).
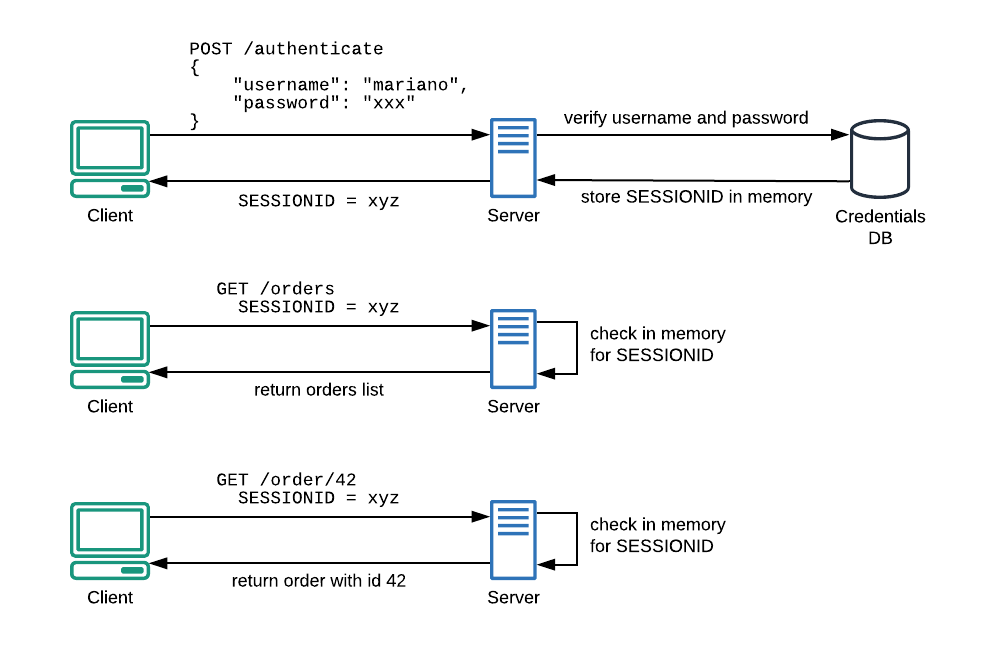 Fig. 2–Using SSS, we reduce the number of authentications towards the Credentials database.
Fig. 2–Using SSS, we reduce the number of authentications towards the Credentials database.
This solution will fix a problem but it will create another one. Probably bigger.
A problem of scale
In the IT world, time goes fast and a solution that yesterday was commonly used, might be outdated now. Server Side Sessions are one of these.
In the API era, our endpoints can face a huge amount of requests, so our infrastructures needs to scale. There are two types of scaling:
vertical scaling – scaling up your infrastructure merely means adding more resources to a server. This is an expensive solution with a low upper limit (i.e. the server’s maximum allocation of resources);
horizontal scaling – scaling out your infrastructure is simpler and more cost-effective as it only involves adding a new server behind a load balancer);
Now it’s seems pretty clear that the second approach will be far most beneficial; but let’s take a look at what may happen.
In the initial scenario, behind the load balancer, there’s just one server. When a client performs a request, using session id xyz, its record will surely be found in the server’s memory (fig.3).
So far, so good.
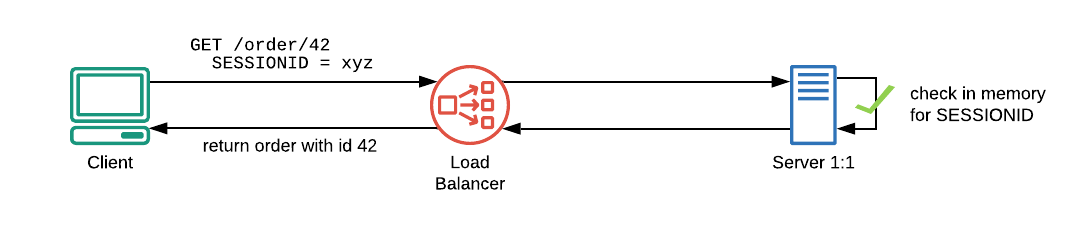 Fig. 3–One single server behind the load balancer. The session id of the request will be found in memory.
Fig. 3–One single server behind the load balancer. The session id of the request will be found in memory.
Now imagine that the above infrastructure needs to scale. A new server (i.e. Server 2:2) will be added behind the load balancer and this brand new server will handle the next request issued by xyz client…
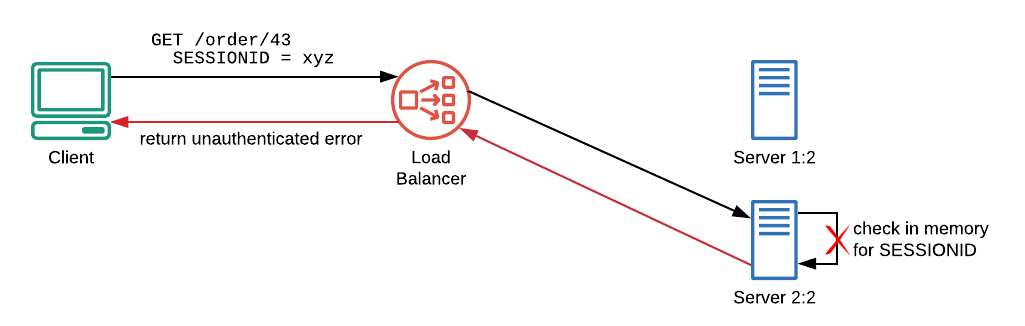 Fig.4–A new server is behind the LB, it knows nothing about the previous session so the user won’t be recognized.
Fig.4–A new server is behind the LB, it knows nothing about the previous session so the user won’t be recognized.
Unauthenticated! The brand new server has no xyz sessions in its memory, so the authentication process will fail. To fix this, we have three main workarounds that can be used:
Synchronize sessions between servers — tricky and error-prone;
Use an external in-memory database — good solution, but it will add another component to the infrastructure;
Third: embrace the stateless nature of HTTP and search for a better solution!
The better solution
JSON Web Token (JWT) is an open standard (RFC 7519) that defines a way for transmitting information –like authentication and authorization facts– between two parties: an issuer and an audience. Communication is safe because each token issued is digitally signed, so the consumer can verify if the token is authentic or has been forged.
Each token is self-contained, this means it contains all information needed to allow or deny any given requests to an API. To understand how we can verify a token and how authorization happens, we need to take a step back and look into a JWT.
Anatomy of a JWT
A JSON Web Token is essentially a long encoded text string. This string is composed of three smaller parts, separated by a dot sign. These parts are:
the header;
a payload or body;
a signature;
Therefore, our tokens will look like this:
header.payload.signature
Header
The header section contains information about the token itself.
{
"kid": "ywdoAL4WL...rV4InvRo=",
"alg": "RS256"
}
The following JSON explains which algorithm has been used to sign the token (alg) and which is the key (kid) that we need to use to validate it. One moment of patience, please, we will look into this soon. :)
The JSON is finally encoded as Base64URL:
eyJraWQiOiJ -TRUNCATED- JTMjU2In0
Payload or body
The payload is the most important part of a JWT. It contains information (claims in JWT jargon) about the client:
{
[...]
"iss": "https://cognito-idp.eu-west-1.amazonaws.com/XXX",
"name": "Mariano Calandra",
"admin": false
}
The iss property is a registered claim, it represents the identity provider that issued the token — in this case, Amazon Cognito. Finally, we can add further claims based on our needs (e.g. admin claim).
The payload is then encoded as Base64URL:
eyJzdWIiOiJkZGU5N2Y0ZC0wNmQyLTQwZjEtYWJkNi0xZWRhODM1YzExM2UiLCJhdWQiOiI3c2Jzamh -TRUNCATED- hbnRfaWQiOiJ4cGVwcGVycy5jb20iLCJleHAiOjE1N jY4MzQwMDgsImlhdCI6MTU2NjgzMDQwOH0
Signature
The third part of the token is a hash that is computed following these steps:
join with a dot the encoded header and the encoded payload;
hash the result using the encryption algorithm specified in
algproperty of the header (in this case RS256) and a private key;encode the result as Base64URL;
Here we can look at it as pseudo-code:
data = base64UrlEncode(header) + "." + base64UrlEncode(payload);
hash = RS256(data, private_key);
signature = base64UrlEncode(hash);
And here it is the computed signature:
POstGetfAytaZS82wHcjoTyoqhMyxXiWdR7Nn7A29DNSl0EiXLdwJ6xC6AfgZWF1bOsS_TuYI3OG85 -TRUNCATED- FfEbLxtF2pZS6YC1aSfLQxeNe8djT9YjpvRZA
Put everything together
Once we have the encoded header, the encoded payload and the encoded signature, we can join everything together simply by merging every piece with a dot:
eyJzdWIiOiJkZGU5N2Y0ZC0wNmQyLTQwZjEtYWJkNi0xZWRhODM1YzExM2UiLCJhdWQiOiI3c2Jzamh -TRUNCATED- hbnRfaWQiOiJ4cGVwcGVycy5jb20iLCJleHAiOjE1N jY4MzQwMDgsImlhdCI6MTU2NjgzMDQwOH0.eyJzdWIiOiJkZGU5N2Y0ZC0wNmQyLTQwZjEtYWJkNi0xZWRhODM1YzExM2UiLCJhdWQiOiI3c2Jzamh -TRUNCATED- hbnRfaWQiOiJ4cGVwcGVycy5jb20iLCJleHAiOjE1N jY4MzQwMDgsImlhdCI6MTU2NjgzMDQwOH0.POstGetfAytaZS82wHcjoTyoqhMyxXiWdR7Nn7A29DNSl0EiXLdwJ6xC6AfgZWF1bOsS_TuYI3OG85 -TRUNCATED- FfEbLxtF2pZS6YC1aSfLQxeNe8djT9YjpvRZA
Note: Even if the above token seems encrypted, it isn’t! Unlike RS256, Base64URL is not an encryption algorithm, so mind your payload!
JWT validation
Since the token is self-contained, we own all the information needed for its validation. For example, we know the token has been signed using RS256 (alg property of the header) and a private key. Now we need to know how to get the right public key to perform the validation. Yes, the public key!
Note: In asymmetric encryption, we all know that a public key is used to encrypt a message, whereas a private key is used to decrypt it. In a signing algorithm, this process is completely switched! Here the message (the
datain the pseudo-code above) is signed using the private key and the public key is used to verify that the signature is valid.
The iss property of the body represents the endpoint of the issuer (Amazon Cognito in our case, but there should be no great differences with other providers), copy that URI and prepend it to the string/.well-known/jwks.json. It should look something like:
https://cognito-idp.eu-west-1.amazonaws.com/XXX/.well-known/jwks.json
Following this URL, we will find a JSON:
{
"keys": [
{
"alg": "RS256",
"e": "AQAB",
"kid": "ywdoAL4WL...rV4InvRo=",
"kty": "RSA",
"n": "m7uImGR -TRUNCATED AhaabmiCq5WMQ",
"use": "sig"
},
{...}
]
}
In the keys array, search for the element that has the same kid of the token’s header. The properties e and n are the public exponent and modulus that compute the public key.
Once we get it, we can verify the signature. If it’s valid, we can be sure that the information contained in the token is trusted.
Note: The process of public key calculation or sign verification is not easy and is beyond the scope of this post.
A real case scenario
At the first access, a client needs to contact the authentication server (Amazon Cognito here, but Microsoft, Salesforce or any other provider should be pretty similar), sending username and password to it. If credentials are valid, a JWT token will be returned to the client that will use it to request an API (in this example Amazon API Gateway endpoint).
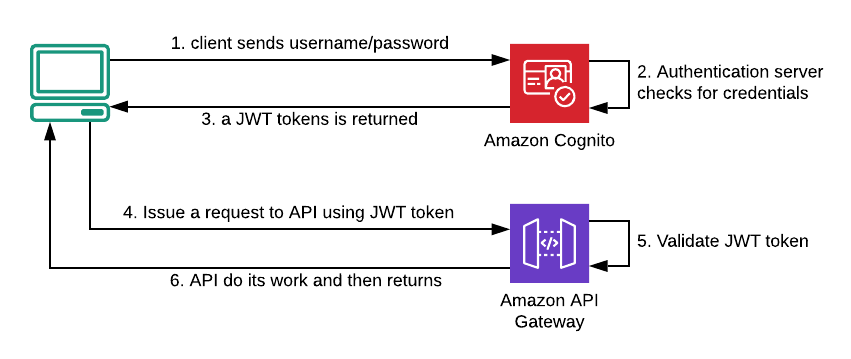 Fig.5 — The complete flow of a real case scenario.
Fig.5 — The complete flow of a real case scenario.
In the above scenario (fig.5), API itself is the only responsible for token validation and it’s able to reject the request if the signature seems forged.
Going further
Suppose a client wants to invoke a protected API to delete an order (e.g. DELETE /order/42) and this action should be only performed by administrators.
With a JWT in place, this operation is hard as add a custom claim to the payload body (i.e. the admin: true claim of the example above). When invoked, the API will first verify the signature authenticity and afterwards, it’ll check if admin claim is true.
Summary
In this article, we have seen many things about JWT with the aim to provide a historical and conceptual perspective of the topic. If you need a more hands-on guide here you can read how to protect APIs with JWT and API Gateway Lambda Authorizer.
That’s all for now but something still misses:
How do we configure Amazon Cognito to get a JWT token?
How do we configure Amazon Cognito to add a custom claim?
Don’t worry, we have room for answering this questions in a later story. For now, let’s summarise some key points:
HTTP protocol is stateless, that means a new request won’t know anything about the previous one;
Server Side Sessions was a solution to the statelessness of HTTP, but these, in the long run, were a threat to our scaling abilities;
JWT is self-contained, that means it contains every information needed to allow or deny any given requests to an API;
JWT is stateless by design, so we don’t have to fight with the stateless design of HTTP;
JWT is encoded, not encrypted have it in mind;
Disclaimer
Stateless nature of HTTP is clearly not a flaw. Just a provocation :)
If you liked this post, please support my work!




