The simple cure for AWS Lambda lock-in fear

Mariano works in Claranet Italia, where he daily helps companies succeed using cloud and microservices.
He's also an AWS Authorized Instructor and AWS Community Builder.
For those of you who might not be familiar with, AWS Lambda is a service platform that let us run our code without provisioning or managing servers. We just upload the source code and the platform takes care of everything required to run and scale it.
Once deployed, that code can be automatically triggered by other AWS services like Amazon S3, Amazon SNS/SQS and so on. To make these integrations as seamless as possible, there are some assumptions and conventions that we need to use.
Since these conventions are peculiar to AWS Lambda, sometimes you may hear of people that are evaluating other platforms, like Kubernetes, just because they are scared to be locked in AWS Lambda for the rest of their life.
Kubernetes is open source and runs on most environments, including on premises. Problem solved? Not quite — now you are tied to Kubernetes — think of all those precious YAML files! So you traded one lock-in for another, didn’t you?
The point is that we can’t run away forever and, sooner or later, we have to accept some sort of lock-in! We have already accepted a language lock-in for our applications. We have probably chosen a database. So we are already locked into something.
Should be clear now that we can’t be “100% lock-in free” so this term should be avoided, in favour of a more appropriate one like switching cost (i.e. the cost that I have to pay if I want to, for instance, switch from AWS Lambda to Amazon ECS).
In this article will be presented two main approaches that will allow us to code our Lambda Functions mitigating a possible switching cost:
Decouple business logic from Lambda handler;
Abstract business logic from service call;
Decouple your business logic from Lambda handler
AWS Lambda is based on conventions: this is necessary to run our code without too much configuration effort. The first convention in place is related to the arguments that our Lambda Function accepts.
There are two main arguments that the Lambda, as platform, inject into each Function:
event source — the information related to the event that triggered the Function’s execution;
execution context — the execution information like the running time, the execution id, the log stream used and so on;
Speaking in pseudo-code our Function will look like this:
function handler(event, context) {
// lines of code
}
Pro-note: Try to imagine your first high-school software project, it probably had many functions (or methods, if you were using an Object-Ordiented paradigm) but only one of these functions was the entrypoint of your project (in OOP we would call it the Main method).
In the same way, your Lambda Function (capital F) can be composed of many functions (or methods) but only one of these will be the entrypoint and it will be the handler function (or handler method).
Forgetting about the execution context for a while and let concentrate on the event source (i.e. the event argument), so we can stick an important concept in our minds: the way a Function is triggered influence the shape of the event source.
For instance, if our Lambda Function is directly invoked using the related API, the event argument will look exactly like its request payload. For instance, if we want to read the value of the property a we can do it through event.a (Fig.1).
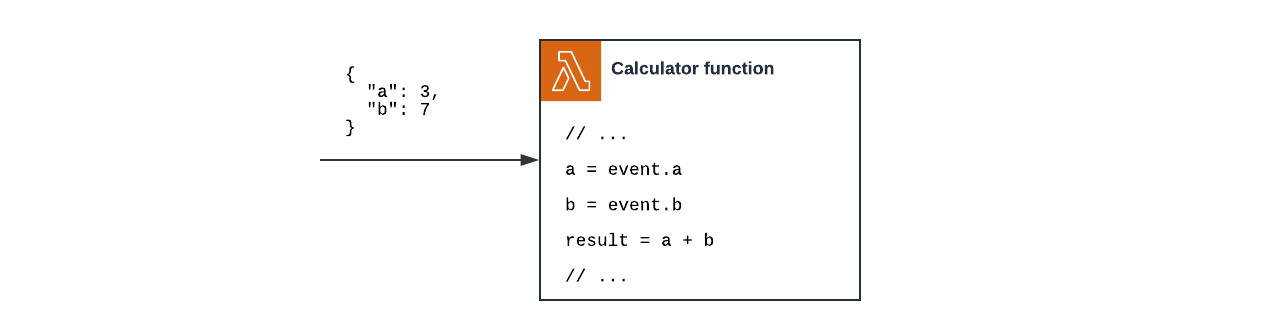 Fig. 1 – Here we are directly invoking the Function (e.g. using the “Test” button in the Lambda console). In this case, the request’s parameters that we sent are forwarded (as is) to the handler through the
Fig. 1 – Here we are directly invoking the Function (e.g. using the “Test” button in the Lambda console). In this case, the request’s parameters that we sent are forwarded (as is) to the handler through the event argument.
But everything changes if our Function is invoked through another service that made the invocation on our behalf. A classic example would be a Lambda Function that is exposed through API Gateway.
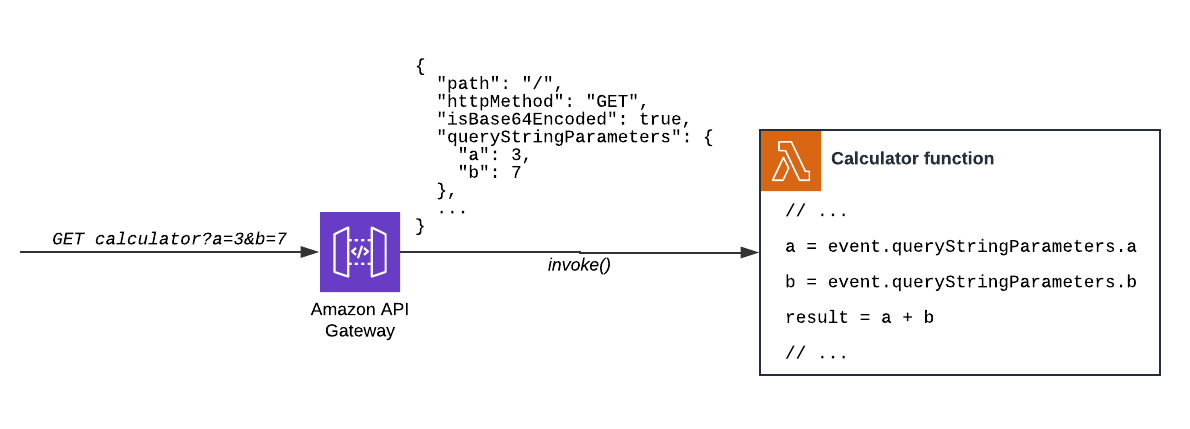 Fig. 2 – Here we sent an HTTP request to an API Gateway endpoint, the latter, on our behalf, will invoke the Function. In this case, API Gateway service will wrap any HTTP information (like the query-string) in a JSON object following a given convention. The entire object is then available inside the handler trough the
Fig. 2 – Here we sent an HTTP request to an API Gateway endpoint, the latter, on our behalf, will invoke the Function. In this case, API Gateway service will wrap any HTTP information (like the query-string) in a JSON object following a given convention. The entire object is then available inside the handler trough the event argument.
For instance, if we want to get the property a from the query-string, we need to look for event.queryStringParameters.a rather than event.a(Fig.2).
But its not over yet! A common approach when Lambda is used as a backend for Amazon API Gateway is to configure the latter using the so-called Lambda proxy integration. To make this work, our Lambda Function has to return an object with three properties: a status-code, a body and optional headers.
To work properly the Lambda behind the GET /calculator?a=3&b=7 (Fig.2), have to look like this:
// filename: lambda.pseudo (v.1)
function(event) {
// 1st part (API Gateway convention)
a = event.queryStringParameters.a // 3
b = event.queryStringParameters.b // 7
// 2nd part (business logic)
body = {"result" : a + b}
// 3rd part (Lambda/API Gateway convention)
body_s = body.stringify() // i.e. "{\"result\" : 10}"
return {
statusCode: 200,
body: body_s,
headers: {"content-type": "application/json"}
}
}
Due to these conventions, a one-line of business logic needs many lines of service code. If we would switch this solution from Lambda into a container on Amazon ECS, we will need to refactor the existing code. We might have a high switching cost!
Note: I completely agree. A sum between two numbers is not a real business logic. Anyway for readability sake I prefered to stick with the most simple scenario.
To lower this cost, we can decouple our code, extracting our logic from the Lambda handler. This task is not hard and we can achieve a good result with a few minutes of refactoring, simply encapsulating the business logic in its component:
// filename: calculator.pseudo
function sum(a, b) {
return {"result": a + b}
}
Now, the Lambda handler is nothing more than service code; here is where we extract the payload sent by API Gateway and translate the business logic into an object that will be API Gateway compliant:
// filename: lambda.pseudo (v.2)
import Calculator from calculator.pseudo
function(event) {
// 1st part (API Gateway convention)
a = event.queryStringParameters.a // 3
b = event.queryStringParameters.b // 7
// 2nd part (instantiate the business logic)
calculator = new Calculator()
result = calculator.sum(a, b) // {"result" : 10}
// 3rd part (Lambda/API Gateway convention)
body = result.stringify() // "{\"result\" : 10}"
return {
statusCode: 200,
body: body,
headers: {"content-type": "application/json"}
}
}
Encapsulating our business logic in a separate file we have more freedom to move. If one day we need to switch we could reuse that business logic.
Abstract business code from provider’s services calls
«It’s over?»
«Not yet!»
It’s really likely that in our business logic, we used the AWS SDK to interact with a backend service, like DynamoDB. In the following code, we sum two numbers and save the result in a DynamoDB table (for sake of simplicity pretend this is somewhat meaningful):
// file: calculator.pseudo (v.2)
import doc_client from AWS.DynamoDB.DocumentClient()
function sum(a, b) {
// calculate the result (your business logic)
result = a + b
// interact with DynamoDB (service code)
params = {
TableName: "Results",
Item: { "value": result, "id": uuid()}
}
doc_client.put(params)
// return the result (business logic)
return {"result": result}
}
Just because we wanted to write something into a database, now we are strictly tied to the AWS SDK and DynamoDB conventions.
We are stuck again!
The Repository pattern
Years ago, when I first set into the industry, the main concern of every architect was the database! The solution to this concern was the Repository pattern.
To explain how a repository works, I like to use the words used by Eric Evans in one of the books that I love the most and I quoted in many other articles:
[A repository] provide methods to add and remove objects, which will encapsulate the actual insertion or removal of data in the data store. Provide methods that select objects based on some criteria and return fully instantiated objects or collections of objects whose attribute values meet the criteria, thereby encapsulating the actual storage and query technology.
With a repository, we can:
• decouple application and domain design from persistence technology […]; • allow easy substitution of a dummy implementation, for use in testing […];
Playing with the code this is simply doable:
// file: calculator.pseudo (v.3)
Calculator(_repository) {
repository = _repository
}
function sum(a, b) {
// calculate the result (your business logic)
result = a + b
// write to a database using the repository
item = { "value": result, "id": uuid()}
repository.save(item)
// return the result (business logic)
return {"result": result}
}
Now that we eradicated the DynamoDB service code from our business logic, we need to encapsulate it somewhere else:
// file: repository.dynamodb.pseudo
import doc_client from AWS.DynamoDB.DocumentClient()
DynamoDbRepository(_tablename) {
tablename = _tablename
}
function save(item) {
params = {
TableName: _tablename,
Item: item
}
doc_client.put(params)
}
All we have to do now is to edit our Lambda handler so it can instantiate the repository and inject it into our business logic:
// filename: lambda.pseudo (v.3)
import Calculator from calculator.pseudo
import DynamoDbRepository from repository.dynamodb.pseudo
function(event) {
// 1st part (API Gateway convention)
a = event.queryStringParameters.a // 3
b = event.queryStringParameters.b // 7
// 2nd part (instantiate the business logic and dependencies)
ddb = new DynamoDbRepository("Results")
calculator = new Calculator(ddb)
result = calculator.sum(a, b)
// 3rd part (Lambda/API Gateway convention)
body = result.stringify() // i.e. "{\"result\" : 10}"
return {
statusCode: 200,
body: body,
headers: {"content-type": "application/json"}
}
}
Pro-note: In a real case scenario, in order to implement a good repository consider the use of interfaces, having in mind the Inversion of Control principle and Dependency Injection.
From Repository to Ports and Adapters pattern
In the same way, if we are afraid of Lambda switching cost and we want to mitigate it, we should design it with repository pattern in mind. Not only for the database but for any external component!
If our application makes some Amazon Simple Notification Service (SNS) calls, we could wrap this communication into a repository. If our application save files into an Amazon Simple Notification Service (S3) bucket we could wrap it into some sort of repository.
From a higher perspective, we are implementing a more broad pattern called Ports and Adapter. The idea behind is that the business logic is the core of our system. All the inputs and outputs reach or leave this core through well-known ports. These ports isolate the application from external technologies, tools or framework. As a side effect, this approach:
allow an application to equally be driven by users, programs, automated test or batch scripts, and to be developed and tested in isolation from its eventual run-time devices and databases.
– Alistair Cockburn
A matter of tradeoffs
In this way, we are abstracted from some low-level details that would cause a high switching cost but we need to ask ourself a question:
«Do it worth the price?»
Yes, absolutely! Mainly because it improves the overall quality of our application, then because it can mitigate a possible switching cost.
Going further, you could be tempted to create a real cloud-agnostic serverless application. Please, don’t do this!!! In this regarding I like this Yan Cui’s tweet that really makes the long story short.
](https://cdn-images-1.medium.com/max/2312/1*p-ELc5Bj2D0vlHRihl1RFg.png) https://lumigo.io/blog/you-are-wrong-about-serverless-vendor-lock-in/
https://lumigo.io/blog/you-are-wrong-about-serverless-vendor-lock-in/
But there’s another issue that can be even more subtle if we can’t anticipate it. There are many definitions to describe a cloud-native application, one that I like the most is an application that wisely use the provider’s features to deliver value to a customer as fastest as possible.
One of these features in AWS are Lambda Destinations, that allows us to write less code — and less code means fewer bugs — delivering a better event-driven application. Unluckily, this feature is strictly related to AWS and encapsulate it through the Ports and Adapters pattern will be difficult, if not impossible.
Should we still use a feature like that?
Conclusions
The answer to the previous question is: It depends! :-)
What I love the most of serverless is the possibility to write code without any concern about the low-level architecture. I also enjoy some features that speed up the development experience giving a great value to the customer (and remember, the customer is the king).
On the other hand, I like to abstract as many things as possible but, it’s more for a testing perspective than a lock-in fear. The more time I spent working on AWS and Lambda, the more they are getting better and better lowering the cost of each service making things robust. For this, I have no fear to be locked in, neither to need to switch.
Whether some well-defined parts of your system, based on your understanding, are so crucial to deserve a multi-cloud or a vendor-agnostic approach go for it and put there your extra-efforts; otherwise don’t overcomplicate your solutions.
My 2 cents.
If you liked this post, please support my work!
Further reading
Gregor Hope — Don’t get locked up into avoiding lock-in;
Mark Schwartz — Switching costs and lock-in;
AWS Doc — Best Practices for Working with AWS Lambda Functions;
Eric Evans — Domain Driven Design: Tackling Complexity in the heart of software;
Slobodan Stojanović — Big bad serverless vendor lock-in;




